Understanding Google’s “Attention Is All You Need” Paper and Its Groundbreaking Impact
With all the buzz around Generative AI, ChatGPT, Bard, etc., it is worthwhile to look at the work that influenced it all. In 2017, a revolutionary paper titled “Attention is All You Need” was released by researchers at Google. This introduction aims to break down the technical jargon and explain the essence and the groundbreaking impact of this paper in simple terms.
Google’s 2017 paper introduced a new neural network architecture called the Transformer, which is based solely on an attention mechanism. The Transformer has since become the dominant model for machine translation and other natural language processing (NLP) tasks, such as text summarization, question answering, and natural language inference.
What is attention?
Attention is a mechanism that allows neural networks to focus on specific parts of their input. This is important for NLP tasks, where the input text can be long and complex. For example, in machine translation, the model needs to be able to attend to the words in the source sentence in order to generate the correct translation in the target sentence.

What is the Transformer Model?
The Transformer consists of two main components: an encoder and a decoder. The encoder takes the input text and produces a sequence of hidden states, which represent the meaning of the text. The decoder then takes the encoder's hidden states and generates the output text, one word at a time.
The Transformer model is a type of machine learning model that has significantly influenced various applications in natural language processing (NLP), such as machine translation, text summarization, and much more. Unlike previous models that processed data sequentially, the Transformer model processes all data concurrently, making it faster and more efficient. The key innovation of the Transformer is that it uses an attention mechanism to allow the decoder to attend to the encoder's hidden states at any position. This allows the decoder to learn long-range dependencies in the input text, which is essential for many NLP tasks.
Key Features:
- Attention Mechanism: It determines which parts of the data the model should focus on at any given time, allowing the model to handle large amounts of data effectively.
- Parallel Processing: All data is processed at the same time rather than sequentially, leading to faster results.
- Scalability: Efficiently handles a broad range of data sizes and complexities.
Understanding Key Concepts
Attention Mechanisms
The “attention” in “Attention is All You Need” refers to the model’s ability to dynamically focus on different parts of the input data, determining which elements are the most relevant for the task at hand. This aspect helps in enhancing the efficiency and accuracy of the model.
Scaled Dot-Product Attention and Multi-Head Attention
Two essential concepts introduced in the paper are scaled dot-product attention and multi-head attention. These concepts help the model focus on the most pertinent information and allow focusing on different parts concurrently, leading to richer and more diverse data representations.

Scaled dot-product attention is a type of attention mechanism that uses a scaled dot product to compute the attention weights. The dot product is a measure of the similarity between two vectors, and scaling it helps to prevent the attention weights from becoming too large.
The scaled dot-product attention function takes three matrices as input:
- The query matrix Q, which represents the queries that the model is trying to attend to.
- The key matrix K, which represents the keys that the model is using to attend to the queries.
- The value matrix V, which represents the values that the model is attending to.
The output of the scaled dot-product attention function is a weighted sum of the values, where the weights are determined by the attention weights.
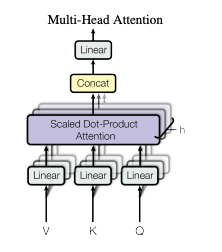
Multi-head attention is a type of attention mechanism that uses multiple scaled dot-product attention heads in parallel. Each head has its own set of query, key, and value matrices. This allows the model to attend to different parts of the input in different ways.
The output of the multi-head attention function is a concatenation of the outputs of the individual heads. This allows the model to learn a richer representation of the input text.
Scaled dot-product attention and multi-head attention are both key components of the Transformer architecture, which is a neural network architecture that has been shown to be very effective for a variety of natural language processing (NLP) tasks, such as machine translation, text summarization, and question answering.
Here is an example of how scaled dot-product attention and multi-head attention can be used for machine translation:
Suppose that we are translating the sentence “I love my dog” from English to French. The Transformer model would first encode the English sentence into a sequence of hidden states. The multi-head attention function would then be used to attend to the hidden states of the encoder, in order to generate the French translation.
Each head of the multi-head attention function would attend to different parts of the encoder hidden states. For example, one head might attend to the words “I” and “love”, while another head might attend to the words “my” and “dog”. This allows the model to learn a richer representation of the input text, and to generate a more accurate translation.
Scaled dot-product attention and multi-head attention are powerful tools that can be used to improve the performance of NLP models on a variety of tasks.
Self-attention is a type of attention mechanism that allows a neural network to attend to different parts of its own input. This is important for NLP tasks, where the input text can be long and complex. For example, in machine translation, the model needs to be able to attend to the words in the source sentence in order to generate the correct translation in the target sentence.
Self-attention is implemented using the scaled dot-product attention mechanism described above. However, in self-attention, the query, key, and value matrices are all the same. This means that the model is attending to different parts of its own input.
Self-attention has been shown to be very effective for a variety of NLP tasks, such as machine translation, text summarization, and question-answering. It is a key component of the Transformer architecture, which is the dominant model for many NLP tasks today.
Here is an example of how self-attention can be used for machine translation:
Suppose that we are translating the sentence “I love my dog” from English to French. The Transformer model would first encode the English sentence into a sequence of hidden states. The self-attention function would then be used to attend to the hidden states of the encoder, in order to learn a richer representation of the input text.
The self-attention function would allow the model to learn long-range dependencies in the input text. For example, the model would learn that the word “love” is related to the words “I” and “my dog”. This information would then be used by the decoder to generate the French translation.
Self-attention is a powerful tool that can be used to improve the performance of NLP models on a variety of tasks. It is a key component of the Transformer architecture, which is the dominant model for many NLP tasks today.
Importance of the Paper
The paper marks a significant shift in machine learning and NLP by introducing a more efficient and powerful model architecture, leading to the development of more advanced models such as BERT and GPT-3, which are used in various applications today.
Real-World Applications
The Transformer model has numerous real-world applications:
- Machine Translation: Powers Google’s translation service, allowing for fast and accurate translations.
- Text Summarization: Helps in efficiently summarizing large texts, making information more accessible.
- Image Captioning: Automatically generates relevant captions for images.
Conclusion
The “Attention is All You Need” paper stands out as a landmark in the world of Natural Language Processing (NLP). It introduced the Transformer architecture, changing the game for using neural networks in NLP tasks. Now, the Transformer leads the way for many NLP tasks and will probably keep doing so for a long time.
Look at how the Transformer is making a difference today:
- Google Translate relies on it to switch text among over 100 languages.
- Facebook’s AI assistant, M, is powered by the Transformer.
- It’s behind Microsoft’s Bing search engine.
- OpenAI’s GPT-3 language model also uses the Transformer.
In essence, the Transformer is a robust and adaptable tool suitable for a broad array of NLP tasks. Its significant impact on the NLP field is set to endure for many more years.
